Scheduling is a large part of making the data center go, and more to the point of making the virtualized (be it VMs, cloud, containers, or clustering) portion of the data center work.
While there are a lot of variables to virtualization performance, scheduling impacts performance all of the time. And yet we only really talk a lot about it in clustering (where a robust scheduler on par with an OS scheduler is required).
There’s a reason for that, and it is worth exploring.
 (Side note: I was talking about this blog with Lori while I was writing it, and she reminded me of when we took our Masters’ courses, the Operating Systems class used Homer Simpsons greedily wanting donuts as our scheduling project. So whenever we think scheduling, we mentally hear one of the many Homer processes being denied a donut and going “D’oh!”)
(Side note: I was talking about this blog with Lori while I was writing it, and she reminded me of when we took our Masters’ courses, the Operating Systems class used Homer Simpsons greedily wanting donuts as our scheduling project. So whenever we think scheduling, we mentally hear one of the many Homer processes being denied a donut and going “D’oh!”)
For virtual machines, scheduling is largely forgone in favor of other resource utilization. Virtualization only cares about CPUs and memory requirements when the virtual machine is created. You tell it then, and the only time you worry about it again is if you demand more CPU cores than the physical hardware can provide—and in some cases, CPU virtualization will allow you to keep spinning up VMs even after that. Only the real scheduling mechanisms actually can be at odds with each other in a heavy load situation. The host OS scheduler, for example, could swap out your VM’s active thread at the same time the guest OS has raised the level of importance for an app to “insanely high, do it now.” Although this only begins to show if basic rules about servers and loads are ignored, it does happen.
You get the same issues with private clouds. Why? Because even though everyone in the marketing world pretends it isn’t true, private cloud and VMware ESXi essentially are the same underlying toolset. And usage patterns in the enterprise show not only does everyone know that, but also the differences are less substantial than any of the organizations involved want to admit. Not that they are the same code, but in practice, they do the same things.




The one place where these two (and public cloud for that matter) really make use of scheduling is when automatically responding to spikes in usage that threaten to bury a system. However, solutions to usage spikes are not part and parcel of these systems; they are crafted by DevOps (or Dev, or Ops) folks who work at places where dropped connections are lost money and, thus, a quick response of growing the pool of available servers and then later shrinking it is important. But because they are using their own metrics to determine the need, more of these systems are implemented in application provisioning tools than in cloud or virtualization software. We could argue about where this functionality actually belongs, but not really where it is implemented today.
I kind of bled into public cloud there, so will address it. When people talk about it being more “agile” or “adaptive,” they mean “with this quasi-scheduling code we wrote to spin up instances at need.” It doesn’t matter if the “code” is a python script or an Ansible playbook—they did the scheduling, not the system.
That leaves clustering software (such as Mesos). Because clustering software treats many machines as one big thing, it requires a scheduler to manage the resources. In the case of Mesos, the central scheduler really isn’t that smart, and I think that is a genius implementation. It knows what resources (CPU, memory) each machine has available, it knows what resources have been assigned from that machine, and for each of the “frameworks” (think of them as job executors; though that’s a bit simplistic, it’s perfect for this discussion) what it needs to get its work done. Then it does a best match, offers resources to frameworks and waits for more resources to come available from finished executions.
So in the world of VMs, if you have 50 unique applications that need resources, you create 50 VMs to service them. In either cloud environment, you do the same. It is a joke we like to make that because of microservices, containers are treated like VMs, except if you have 50 unique applications, you create 500 containers, but the reality is that they are exactly like VMs in many use cases, and make 50 containers when containerizing existing apps. Taking a look at MesoSphere’s 2016 survey of clustering users, you can see that a fair number of clustering users are using containers with Mesos and DC/OS, while many of them are not doing it exclusively with microservices.
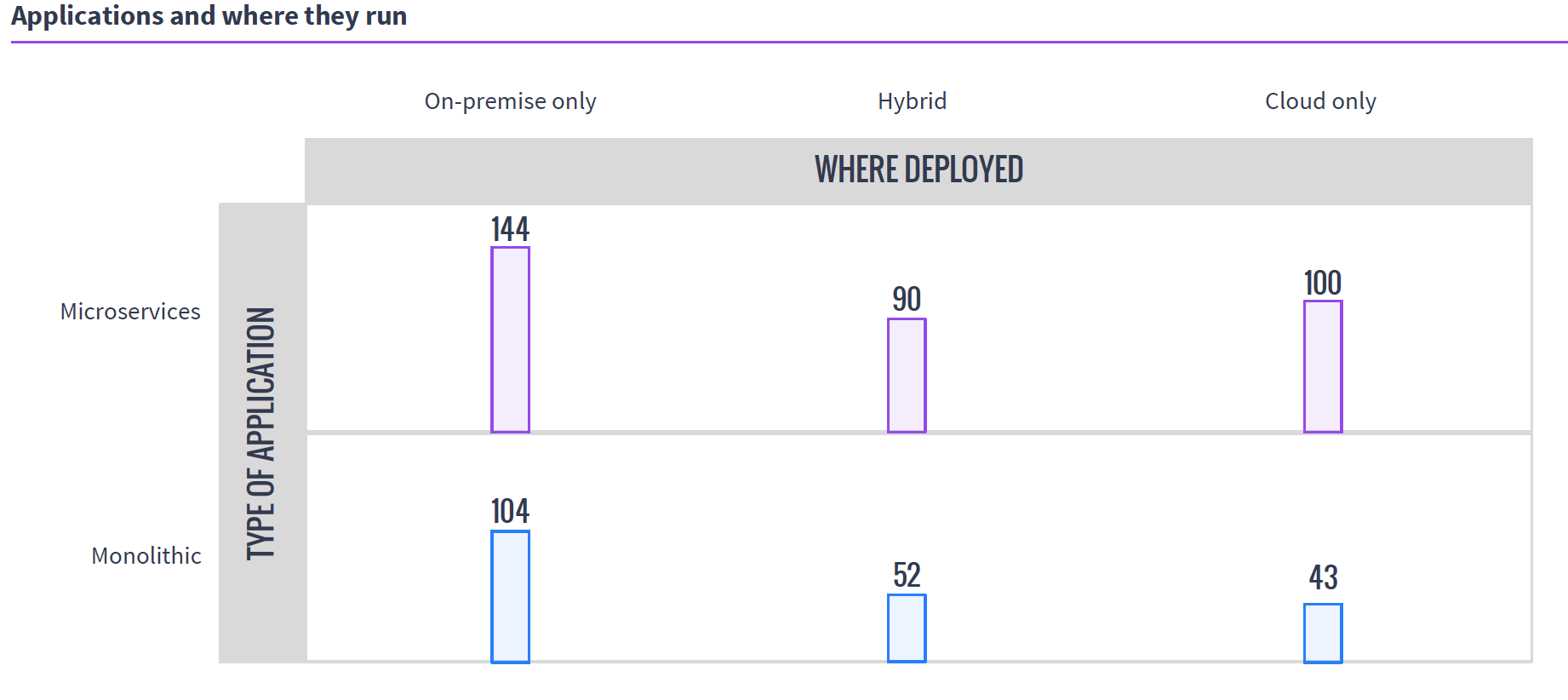
Source: MesoSphere user survey, August 2016
In the clustering world, you have what presents as one big monster machine that is going to run these applications as resources come available, so if your 50 applications require fewer resources than the cluster offers, they simply execute in parallel; if you don’t have enough hardware to run them, unlike with VMs, you can just queue them up and, assuming the cluster isn’t over-burdened, eventually they all will run.
This gets more interesting when containers are added to clustering (a common environment), because then you do have discrete containers, but the scheduler still manages how many resources are available/in use, and the container architecture allows the app to carry its requirements with it across the cluster.
Why do we care? Because you know what your workloads are and which scheduling methodology is more important to your organization. If there are 50 applications that all have steady resource needs and run all of the time, then virtualization might be right for you, but if the organization’s workloads are shifting constantly and resources need to be cycled at a high rate, clustering might be right for you. Either way, knowing what’s out there is never a hindrance.
