It is quite interesting to envision how we could adopt the Hadoop eco system within the realms of DevOps. I will try to cover it in upcoming series. Hadoop managed by the Apache Foundation is a powerful open-source platform written in java that is capable of processing large amounts of heterogeneous data-sets at scale in a distributive fashion on cluster of computers using simple programming models. It is designed to scale up from single server to thousands of machines, each offering local computation and storage and has become an in-demand technical skill. Hadoop is an Apache top-level project being built and used by a global community of contributors and users.
Hadoop Architecture:
The Apache Hadoop framework includes following four modules:
- Hadoop Common: Contains Java libraries and utilities needed by other Hadoop modules. These libraries give filesystem and OS level abstraction and comprise of the essential Java files and scripts that are required to start Hadoop.
- Hadoop Distributed File System (HDFS): A distributed file-system that provides high-throughput access to application data on the community machines thus providing very high aggregate bandwidth across the cluster.
- Hadoop YARN: A resource-management framework responsible for job scheduling and cluster resource management.
- Hadoop MapReduce: This is a YARN- based programming model for parallel processing of large data sets.
Below diagram portray four components that are available in Hadoop framework.
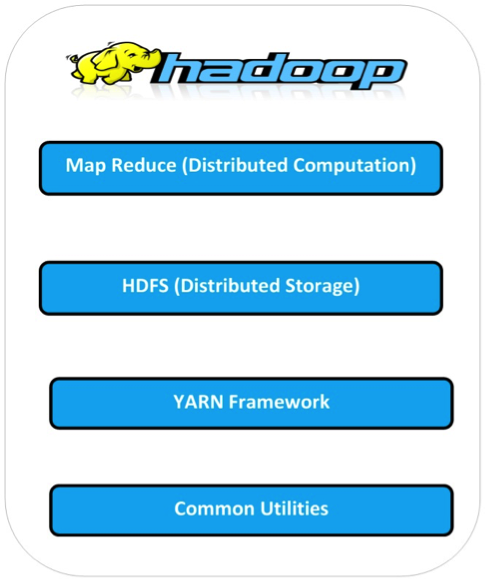
All the modules in Hadoop are designed with a fundamental assumption i.e., hardware failure, so should be automatically controlled in software by the framework. Beyond HDFS, YARN and MapReduce, the entire Apache Hadoop “platform” is now commonly considered to consist of a number of related projects as well: Apache Pig, Apache Hive, Apache HBase, and others.
Hadoop Ecosystem:
Hadoop has gained its popularity due to its ability of storing, analyzing and accessing large amount of data, quickly and cost effectively through clusters of commodity hardware. It wont be wrong if we say that Apache Hadoop is actually a collection of several components and not just a single product.
With Hadoop Ecosystem there are several commercial along with an open source products which are broadly used to make Hadoop laymen accessible and more usable.
The following sections provide additional information on the individual components:
MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process big amounts of data in-parallel on large clusters of commodity hardware in a reliable, fault-tolerant manner. In terms of programming, there are two functions which are most common in MapReduce.
- The Map Task: Master computer or node takes input and convert it into divide it into smaller parts and distribute it on other worker nodes. All worker nodes solve their own small problem and give answer to the master node.
- The Reduce Task: Master node combines all answers coming from worker node and forms it in some form of output which is answer of our big distributed problem.
Generally both the input and the output are reserved in a file-system. The framework is responsible for scheduling tasks, monitoring them and even re-executes the failed tasks.
Hadoop Distributed File System (HDFS)
HDFS is a distributed file-system that provides high throughput access to data. When data is pushed to HDFS, it automatically splits up into multiple blocks and stores/replicates the data thus ensuring high availability and fault tolerance.
Note: A file consists of many blocks (large blocks of 64MB and above).
Here are the main components of HDFS:
- NameNode: It acts as the master of the system. It maintains the name system i.e., directories and files and manages the blocks which are present on the DataNodes.
- DataNodes: They are the slaves which are deployed on each machine and provide the actual storage. They are responsible for serving read and write requests for the clients.
- Secondary NameNode: It is responsible for performing periodic checkpoints. In the event of NameNode failure, you can restart the NameNode using the checkpoint.
Hive
Hive is part of the Hadoop ecosystem and provides an SQL like interface to Hadoop. It is a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop compatible file systems.
It provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. Hive also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
The main building blocks of Hive are –
- Metastore – To store metadata about columns, partition and system catalogue.
- Driver – To manage the lifecycle of a HiveQL statement
- Query Compiler – To compiles HiveQL into a directed acyclic graph.
- Execution Engine – To execute the tasks in proper order which are produced by the compiler.
- HiveServer – To provide a Thrift interface and a JDBC / ODBC server.
HBase (Hadoop DataBase)
HBase is a distributed, column oriented database and uses HDFS for the underlying storage. As said earlier, HDFS works on write once and read many times pattern, but this isn’t a case always. We may require real time read/write random access for huge dataset; this is where HBase comes into the picture. HBase is built on top of HDFS and distributed on column-oriented database.
Here are the main components of HBase:
- HBase Master: It is responsible for negotiating load balancing across all RegionServers and maintains the state of the cluster. It is not part of the actual data storage or retrieval path.
- RegionServer: It is deployed on each machine and hosts data and processes I/O requests.
Zookeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization and providing group services which are very useful for a variety of distributed systems. HBase is not operational without ZooKeeper.
Mahout
Mahout is a scalable machine learning library that implements various different approaches machine learning. At present Mahout contains four main groups of algorithms:
- Recommendations, also known as collective filtering
- Classifications, also known as categorization
- Clustering
- Frequent itemset mining, also known as parallel frequent pattern mining
Algorithms in the Mahout library belong to the subset that can be executed in a distributed fashion and have been written to be executable in MapReduce. Mahout is scalable along three dimensions: It scales to reasonably large data sets by leveraging algorithm properties or implementing versions based on Apache Hadoop.
Sqoop (SQL-to-Hadoop)
Sqoop is a tool designed for efficiently transferring structured data from SQL Server and SQL Azure to HDFS and then uses it in MapReduce and Hive jobs. One can even use Sqoop to move data from HDFS to SQL Server.
Apache Spark:
Apache Spark is a general compute engine that offers fast data analysis on a large scale. Spark is built on HDFS but bypasses MapReduce and instead uses its own data processing framework. Common uses cases for Apache Spark include real-time queries, event stream processing, iterative algorithms, complex operations and machine learning.
Pig
Pig is a platform for analyzing and querying huge data sets that consist of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. Pig’s built-in operations can make sense of semi-structured data, such as log files, and the language is extensible using Java to add support for custom data types and transformations.
Pig has three main key properties:
- Extensibility
- Optimization opportunities
- Ease of programming
The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets. At the present time, Pig’s infrastructure layer consists of a compiler that produces sequences of MapReduce programs.
Oozie
Apache Oozie is a workflow/coordination system to manage Hadoop jobs.
Flume
Flume is a framework for harvesting, aggregating and moving huge amounts of log data or text files in and out of Hadoop. Agents are populated throughout ones IT infrastructure inside web servers, application servers and mobile devices. Flume itself has a query processing engine, so it’s easy to transform each new batch of data before it is shuttled to the intended sink.
Ambari:
Ambari was created to help manage Hadoop. It offers support for many of the tools in the Hadoop ecosystem including Hive, HBase, Pig, Sqoop and Zookeeper. The tool features a management dashboard that keeps track of cluster health and can help diagnose performance issues.
Conclusion
Hadoop is powerful because it is extensible and it is easy to integrate with any component. Its popularity is due in part to its ability to store, analyze and access large amounts of data, quickly and cost effectively across clusters of commodity hardware. Apache Hadoop is not actually a single product but instead a collection of several components. When all these components are merged, it makes the Hadoop very user friendly.
