Security guardrails are an incredible way to keep our cloud deployments safer without slowing things down. Taking this structured approach will minimize friction while increasing protection.
When I first started working hands-on in cloud (AWS) around nine years ago, I quickly realized both the power and risks of just how darn fast and agile cloud could be. Being, on occasion, an optimist, I decided this capability was a significant upgrade to our security capabilities. Sure, I could accidentally spin up internet-exposed servers, but in exchange I gained levels of central control and visibility unheard of in traditional infrastructure.
One of the most powerful new capabilities is the ability to leverage cloud APIs and automation to build automated security guardrails without having to spend a gazillion dollars for a big box that actually delivers as promised, but also adds tremendous friction and slows things down. Guardrails are automations that constantly watch your deployments, find deviations from desired baselines and can even automatically remediate issues. Yet, even cloud-native guardrails can become problematic if they aren’t designed properly. Having both built a fair few myself and worked with many organizations as they built out their cloud security programs, here are some of the lessons I’ve learned along the way and some code to show you how it works.
Building Awesome Guardrails
My first guardrails were a bit of a hodgepodge in terms of structure and capabilities. And practically speaking, there are a lot of ways to attack the problems. Even today I’ll take different approaches depending on the particular challenge in front of me, but most of my guardrails (including operational ones) tend to follow a consistent pattern:
- Define the problem: I like to start by defining the business outcome we want, and then move onto the technical problem. I used to start with a narrow technical problem to solve but found that didn’t always lead me to the right outcome. For example, is the problem that we want to stop all internet-facing port 22 access, or is the real outcome we don’t want to expose internet-facing admin servers to the open internet and we want to use a guardrail to restrict to our known corporate IPs instead? This helps prevent a guardrail from becoming a blocker.
- Set the scope: Multiple cloud accounts (or subscriptions/projects for you Azure/GCP people) are now the standard. The first step is to determine how broad a guardrail you want, which will also define some of the technical specifications. For example, if you want it to apply to multiple accounts in Amazon Web Services, that affects where you run it from and how you manage the required IAM privileges.
- Build or pick the deployment model: There are a lot of technical specifics regarding where and how to run your guardrail. Today’s example will run in AWS within a single account, but if you manage a larger, enterprise-class deployment you will need to look at how and when to balance centralized and localized guardrails. More often than not, I prefer a serverless approach (FaaS with other supporting PaaS), but I’ve also found longer-running guardrails often need containers as well. Thanks to API gateways, it isn’t bad to build deployments that can support both.
- Define filters: It’s awesome that you can automatically close all internet-facing security groups with 20 to 40 lines of code—right until you break a production application. Filters allow you to tune your guardrail for a particular environment or project’s needs. Basic filters might work on a simple resource tag, while more complex filters might evaluate a combination of include and exclude rules for greater flexibility. This can, for example, treat development and production environments differently from the same guardrail.
- Determine triggers: We have a rich range of trigger options on the major cloud platforms today. The main categories are time-based assessments and event-based triggers. I tend to use both, with event-based for more deterministic events (an S3 bucket policy was changed) and time-based sweeps to catch conditions I might miss purely on an event trigger.
- Perform the analysis: This is the meat of our guardrail. Based on the trigger, collect the information we need and, in combination with our scope and filters, make a decision. For example, if we find port 22 open to the internet, if it is a Dev environment we might decide to update the security group to restrict to known corporate IP addresses. If it is in Prod we might delete the rule completely unless it was implemented through a CloudFormation template that went through an approval process.
- Send notifications: Even when you have a completely automated guardrail, you likely want a parallel notification. These can go straight to email/text/Slack or drive into a ticketing system. For security guardrails, I also recommend sending them to your SIEM or other security alert/management system. If you’re fancy, you can turn these into the first step of a chatOps process.
- Take actions: Actions are what separates guardrails from all the annoying alerts of the past. Based on the analysis and filters, actions can be fully automated remediations or request human intervention. Actions also can follow different paths based on the conditions to provide the best options for that situation. The key is that even if a human is called to make a decision, the decision should be a simple click to run the action, saving the person from having to fix things manually. Unfortunately, we still sometimes need human beings to make a decision. Then again, the alternative is bowing down to our robotic overlords. It’s a trade-off, I suppose.
- Validate and log: Don’t assume the action actually did anything. Rechecking is vital, as is logging and sending the results as a second notification to the ticketing system/SIEM/etc. I fully recommend sending both incident open and close notifications to the destination system, even if the guardrail fixed everything within seconds. This keeps a consistent record and also allows you to do nifty things such as measure your mean resolution time and compare automated versus manual.
Running a Demonstration Guardrail
One of my favorite guardrails to demonstrate is automatically reversing security group changes in AWS. Here’s how to set it up for yourself and run my demonstration code to see what it looks like:
- The first step is to make sure you don’t start running this in production or anyplace else where you might break things before you actually tune the filters. If you do, it isn’t my fault. The desired outcome in this case is ensuring we don’t have network exposures due to unapproved security group changes on designated resources.
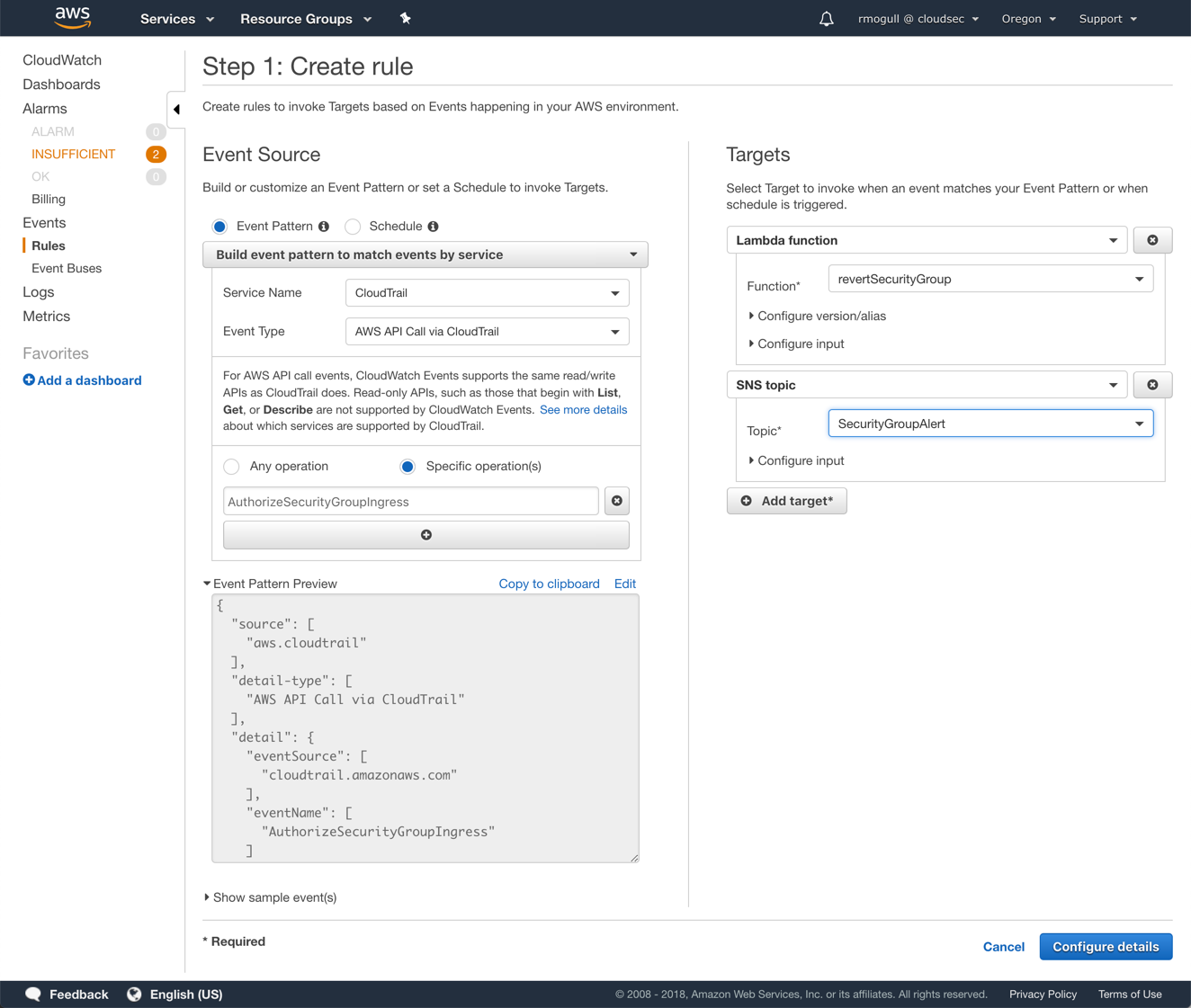
- The scope of this guardrail is a single local account, with a corresponding deployment model. We will use CloudTrail, CloudWatch Rules, Lambda and SNS.
- There are three prep steps to configure your account before building the guardrail:
- Log into the AWS console and set up a destination for notifications. If you haven’t done this before, you want to use SNS (Simple Notification Service). Create a topic for security alerts and a subscription to wherever you want to send the alerts. I recommend starting with a simple email subscription.
- Make sure you have CloudTrail turned on and streaming to CloudWatch. For you newbies, CloudTrail records (almost) all the API calls on your account and we need this for our trigger. Sending the logs to CloudWatch allows us to build near real-time triggers in CloudWatch based on events such as the API call we will look for.
- Create an IAM Role for Lambda to use. It will need the rights to AuthorizeSecurityGroupIngress, DescribeSecurityGroups and RevokeSecurityGroupIngress. To save logs, it also needs PutLogEvents, CreateLogStream and CreateLogGroup. These are also in a JSON template in the project repository for cut and paste.
- With that in place, create a new Lambda function (Python 2.7) and load in our code located at https://github.com/disruptops/RevertSecurityGroups.
- Now go to CloudWatch Rules and create a new rule. For the trigger, use the following:
- Service Name: CloudTrail
- Event Type: AWS API Call via CloudTrail
- Specific Operations: AuthorizeSecurityGroupIngress
- Then set two targets: your Lambda Function and your SNS topic for security alerts. This will revet the changes and simultaneously send you a notification.
This should now revert any new ingress rules added to a security group. If you play with the code you can also use this for egress rules. This is just demo code and there are edge cases it will miss.
The code also includes a number of filter options, including:
- Restricting to a region or VPC.
- Restricting based on a tag or a specific security group ID.
- Allowing the change if it comes from a designated IAM user, and reversing if it was originated by anyone else.
It takes the action automatically; if you want to manually review first you would modify the code to send a notification instead. We have some alternative examples posted at https://github.com/disruptops/demos-tools. These includes some samples that protect S3 and also show how to embed notifications in the Lambda itself for more-flexibility.
Hopefully this gives you some ideas to refine your own guardrails to dramatically improve security while still moving blazingly fast.
