One of the biggest problems in modern distributed computing is data management. These days data are spread out all over the place. As a result, getting the data you need, exactly when you need it, becomes a problem. Wider distribution creates more network latency. If you have a system in which some machines are in California and others are in New York, logic dictates it’s going to take more time for data to travel coast to coast than from within the same geolocation. It’s a matter of common sense.

The data management problems created by distributed systems became more pronounced with the growth of the internet, which is, by nature, highly distributed. Eric Brewer, a computer scientist at the University of California, Berkeley, published a paper in 1999 that describes the dynamics of data management in a distributed system as a set of immutable constraints. Brewer published the work as the CAP principal. Three years later Seth Gilbert and Nancy Lynch at MIT proved the principal to be a theorem. Today, the CAP theorem is a central consideration when designing and implementing applications at web-scale.
Simply put, the CAP theorem asserts that when your data is distributed over a variety of machines and geolocations, if you want the latest, most accurate data, you’re going to have to wait. And, if you don’t want to wait, the data you get will probably be stale. However, if data resides on a single machine, then everything changes. In such a case, you can have the latest data on demand, at any time.
Of course, having a single data source implies having a machine that supports the demands of web-scale. Sadly, the x86 machine has yet to be made that can fit the bill. But a mainframe can. And, not only can it handle an enormous operational load, under the right set of circumstances it also can be a cost-effective way to meet the need at hand.
Allow me to elaborate.
The CAP Theorem Explained
Before we go into the details as to why a mainframe computer such as an IBM Z or LinuxONE can make the problems presented by the CAP theorem go away at a reasonable price, let’s look at the theorem itself.
Essentially, the CAP theorem asserts that of the three aspects of data management in a distributed system—consistency (C), availability (A) and partition tolerance (P)—you can have only two at any point in time.
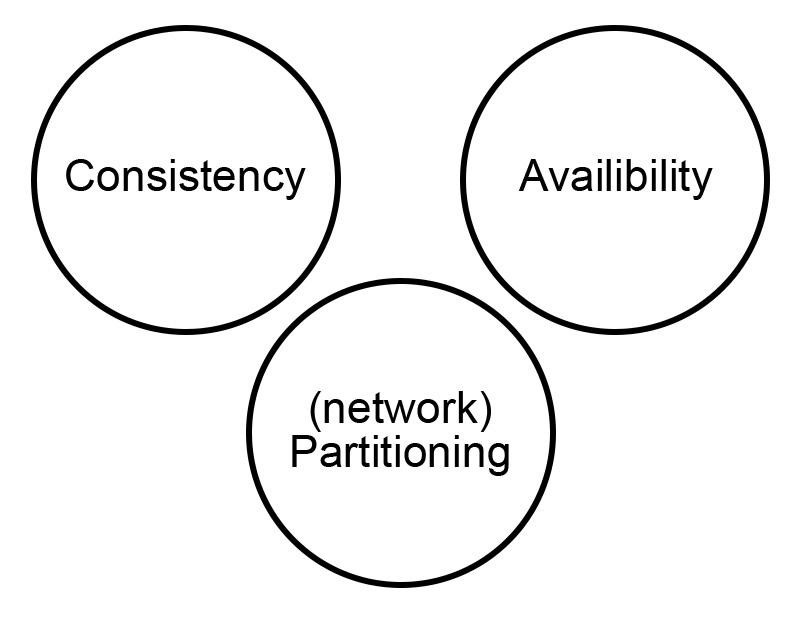
In other words, if you want the latest information (consistency) from your data source immediately (availability), that information needs to be stored in a single, fail-safe location (partition tolerance). If you want to spread the data out over many machines (partition tolerance), either the data will be accurate at some point in time but not immediately (consistency) or you can have data immediately but it might be stale, awaiting an update to the most recent state (availability).
The CAP theorem is more than theoretical. It has an actual operational impact on companies. A telling example is a problem that Netflix experienced when implementing its Monet system.
Netflix Gets CAP-Ped
Back around 2018, Netflix decided to implement an internal ad management tool under design using GraphQL, an open source API specification originated at Facebook that was becoming popular in many companies that operate at web-scale. In fact, GraphQL is still growing in popularity. So Netflix decided to take the plunge toward adopting GraphQL with an internal project named Monet.
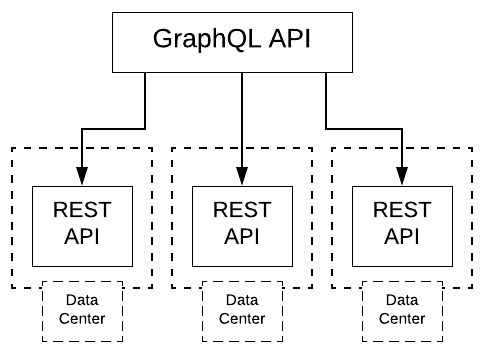
The way Netflix decided to implement Monet was to have the GraphQL API server act as a facade for existing RESTful APIs. The thinking was to reap the benefits provided by GraphQL, yet reuse as much existing code as possible. The idea was good, the actual deployment fell short. Once Monet was put into production, it ran dog slow.
It turns out the REST APIs were distributed among a variety of data centers (see Figure 2). Network latency was killing them.
The company’s solution was to bring all the REST APIs into a single data center (see Figure 3).
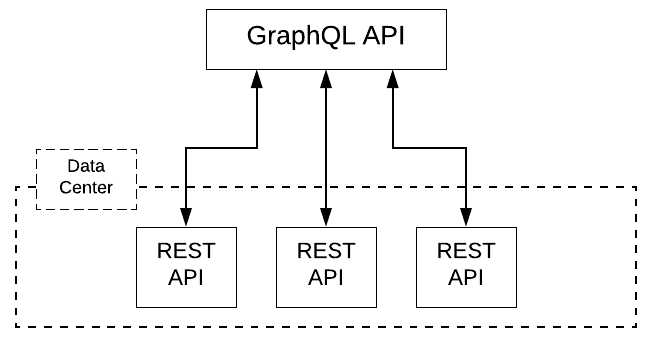
The result? Once all data resided in the same data center, performance improved dramatically. It makes sense. Shorter distance to travel means less latency in the system overall.
Now, how this relates to the CAP theorem is interesting. Remember, according to CAP, as partitioning goes down (P), consistency (C) and availability (A) go up. So, while it’s true that Netflix was not using a single machine as a data source, moving everything into a single data center created what one could consider a single virtual data source. Yes, there might be latency issues within the data center. But, rack-to-rack latency is nowhere near as high as the latency between geolocations. We’re talking the difference of 1 to 10 milliseconds as opposed to hundreds, if not thousands, of milliseconds.
In Netflix’s case, the company addressed the constraints imposed by the CAP theorem by reducing the breadth of partition at the geolocation level. All the data lived in the same data center. Imagine if partition size could be reduced at the machine level. What if instead of having data distributed among many machines within the same data center, data actually resided within a single machine? Partition size would be reduced to one. Then, applications could have the latest data immediately. All that’s needed is a single machine that can handle the load. This is where using a mainframe comes into play.
Mainframes Are Built for Big Data and Agile DevOps
Mainframes since their inception were intended to be able to store and process enormous amounts of data. Today 80% of the world’s data still resides on mainframes. As mentioned in a previous article about this topic, one mainframe can process 2.5 billion transactions daily. That’s the equivalent of 100 Cyber Mondays in a single day. That’s a lot of computing power easily equivalent to more than a few racks of commodity hardware in a data center. In fact, in some situations, one mainframe can provide the computing power found in an entire data center.
So, let’s go back to the Netflix problem. What if instead refactoring those distributed RESTful APIs into a single data center, the time and money spent was used to refactor those RESTful APIs into a single mainframe? Yes, there are some technical hurdle to overcome, but considering the running Linux on a mainframe is standard these days, it’s not as if we’re talking transforming a bunch of Python code into COBOL. Databases from standard RDBMS such as DB2, Oracle to the NoSQL MongoDB can run perfectly well on a mainframe. There’s work to be done, but reinventing the wheel is not one of the tasks. Using a mainframe is a viable solution except for one sticky little problem: The conventional thinking is that using a mainframe is prohibitively expensive. Thus, the bias toward racks of commodity hardware or simply going with a cloud service.
Mainframes as a Cost-Effective Solution
The general perception in most IT shops is only big banks, insurance companies, governments and large-scale manufacturers use mainframe computers. They’re just too expensive for small to medium-size business. While many mainframes come with a price tag that can exceed $1 million, there are still surprisingly affordable models. For example, an entry-level IBM z114 will run about $75,000.
If you’re a company spending $50,000 a month on AWS or Google Cloud computing resources, then for the $600,000 a year cost you’re spending on a cloud provider and the latency that comes with it, your company can well afford not only an entry-level IBM Z system to handle a production load, but also a second one to serve as backup, should failure occur.
In terms of system administration, just about all the tools commonly used to support modern CI/CD processes today in the DevOps world have corresponding equivalents for mainframe implementation. As with any adoption of unfamiliar technology, there is a learning curve. But, again, we’re not reinventing the wheel. The tools, resources and expertise exist. Adoption is just a matter of following standard change management practices typical in medium-to-large-size companies that are well-positioned and use a mainframe to take advantage of implementing a cost-effective, no-partition data source strategy.
Integrating Mainframe Technology into a DevOps-Driven Ecosystem
Mainframes are capable of doing DevOps in an open, agile and collaborative fashion. The tools, resources and expertise required to support a mainframe’s participation in CI/CD processes exist today. For example, Zowe is an open source software framework that provides solutions that allow development and operations teams to securely manage, control and develop on the mainframe like any other platform. DB2 DevOps Experience for z/OS is one of the first commercial products built on Zowe. It allows IT the control over the mainframe database, its business rules and standards, while allowing development teams the ability to work independently using self-services and integration with modern CI/CD tools to speed their application release time with better quality and development practices.
When you think about it, in certain mission-critical situations, using a mainframe to have the latest data at any time not only makes sense from a technological point of view, but it’s also attractive in terms of return on investment. The trick is to be able to identify the right use case. Of course, if you have a situation in which 90% of your users are in California and you have a mainframe situated in Bangalore, the laws of physics will apply. Moving the bits from the mainframe to user will take time. But, if you have situations in which user and data are in continental proximity, using a mainframe as a standard data source begins to look very attractive.
Again, having the right use case is key. But, everything else being equal, using a mainframe for sensitive, data-driven applications warrants significant consideration.
Putting It All Together
The constraints on distributed computing imposed by the CAP theorem remain a challenge to those who design and implement large applications at web-scale. The “pick two” limitation CAP imposes can be an annoyance for simpler websites that provide content intended for the general consumer. But, for large scale, data-intensive applications, having accurate data immediately is not optional, it’s essential. Thus, using mainframe technology to create a no-partition data infrastructure becomes a viable way to address the limitations imposed by the CAP theorem. Under the right conditions, making a mainframe the central repository for your application’s data provides a significant return on investment hard to match when compared to commodity-based cloud providers.
The nice thing about using a mainframe is when it comes to the CAP theorem, you still only get to pick two, but the two you get to pick are consistency and availability. In the scheme of things, those are the two that count.
