In part one of this blog series, we looked at our approach to migration by leveraging the Azure data factory, tuning the performance of Data Factory Pipeline, using Parquet files and increasing computing power.
In this blog, we’ll look at some of the challenges encountered during the migration, cost-saving actions and our approach to data validation.
Challenges Encountered
- Data Factory export failed for tables if the column name had spaces or special characters. In such cases, aliases were used (replacing spaces with an underscore) for column names and the query method was used as a source.
- Data Factory export failed for the column data type “Geography” and had to be cast to varchar and then exported to Blob.
- Some column names in SQL server were keywords in Snowflake, which didn’t allow it to migrate. For example, ‘LOCALTIME’ is a column name in SQL but is also a keyword in Snowflake, and it is addressed using inverted commas as escape characters (“”) while creating the Snowflake table.
- During ingestion into Snowflake, the flat files were named after tables, listing files based on the name pattern. For example, if we wanted to list the file with table name test_1, Snowflake would list all the files starting with the name test_1. It is essential to make sure that each file name is unique.
- If the file to be ingested was incorrect with respect to the table, Snowflake did not return any error messages or warnings. It simply ingested the file and put NULL wherever column mapping was not found.
- While creating the tables, if the column name had spaces, escape characters were used so that the same spaces could be maintained. But for ingestion of such columns, the column mapping from a flat file would be the same aliases that were used in the source query.
- Triggers and compute columns were not supported in Snowflake and had to be eliminated while creating the tables.
- Also, data types that did not exist in the Snowflake schema had to be changed, keeping in mind the correctness of data.
Cost-Saving Actions
- Use of the Parquet file facilitated a compression rate of up to 75%. The 800GB of data was compressed to 234GB in multiple files which reduced the storage cost of Blobs.
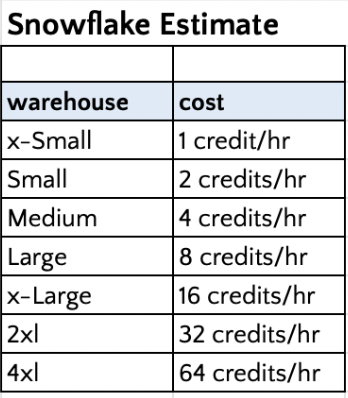
- Detailed POC and analysis discovered that Snowflake ingestion was optimal with Small for moderate sized tables and Medium for large sized tables which kept Snowflake costs in check.
- Self-hosted IR saved on the data pipeline operating cost as the compute power of Azure VM was used.
Cost Estimation

Data Validation
The vital part of the project was ensuring that the integrity and correctness of the data were maintained during the migration process. As a part of standard DataOps best practices, a thorough data validation activity was performed to make sure that the data stayed meaningful and remained of use to drive business decisions.
The approach to data validation was two-fold:
In the first approach, all the distinct data types in the SQL server that were part of the db migration were listed and sampled randomly across one row per data type. The same row was fetched from Snowflake and matched.
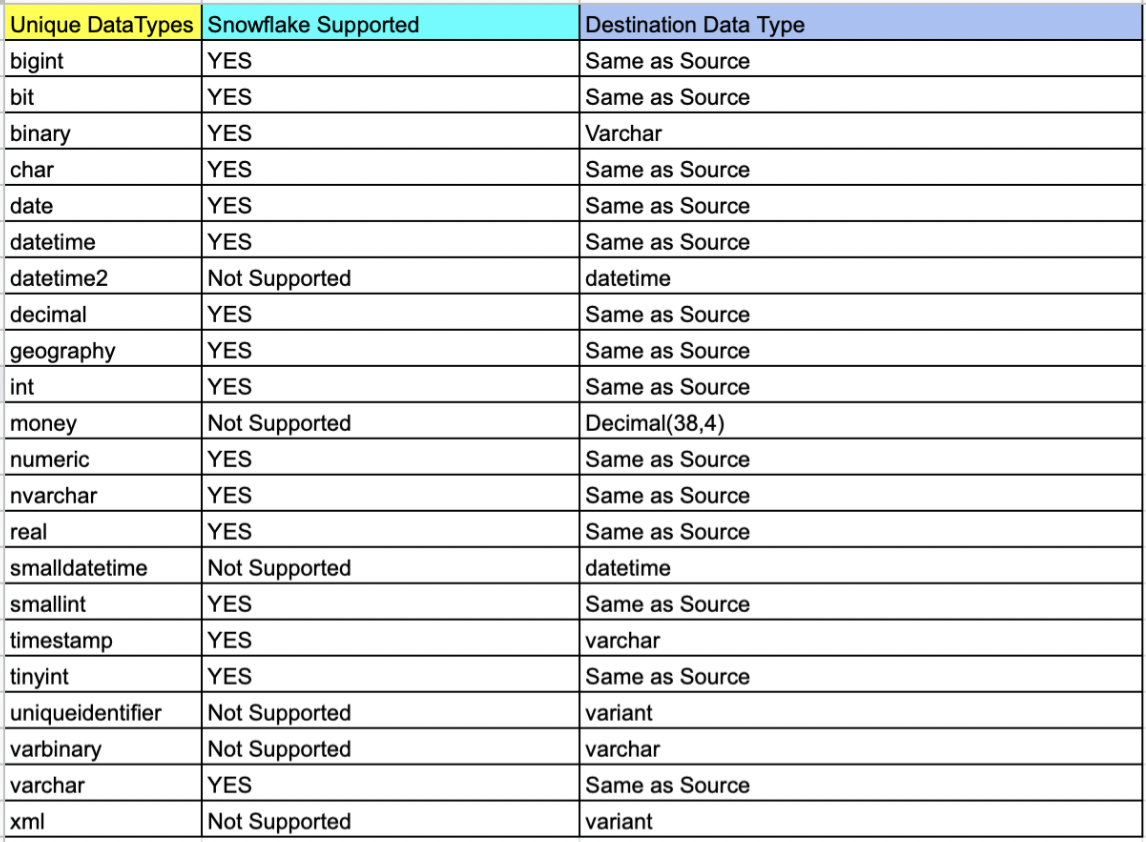
List of tables based on data type
select table_catalog,table_schema,table_name,COLUMN_NAME,* from
INFORMATION_SCHEMA.COLUMNS
where DATA_TYPE = 'money' and TABLE_NAME not like 'sys%'
Issues like that shown below were uncovered in this validation process and were corrected for all instances of the data type.

The second approach involved writing an automated script that accomplished the following results (More details can be found here):
- Script touched each table of each database
- A set of five records were randomly sampled from both sides and matched
- If the tables were empty, it was recorded as tables with zero records
- If the sample sets did not match the script, it wrangled the sets and sorted them one column at a time. If the sample matched the script, it was recorded. This wrangle took care of the scenario wherein the first n number of columns had duplicate records
- Any failed validation attempt would be visible in a generated log report:
Validation Started for Table: Test1
—-> Validation Passed for table Test1
Validation Started for Table: Test2
—-> Validation Passed for table Test2
Validation Started for Table: Test3
—-> Table has 0 records
Validation Started for Table: Test4
—-> Validation Failed for table Test4
Validation Started for Table: Test5
—-> Validation Passed for table Test5
============= Report =============
# Total Number of Tables Scanned: 5
# Tables with 0 records: 1
# Passed: 3
# Failed: 1
# Percentage 60.5556123
