Tag: incident response
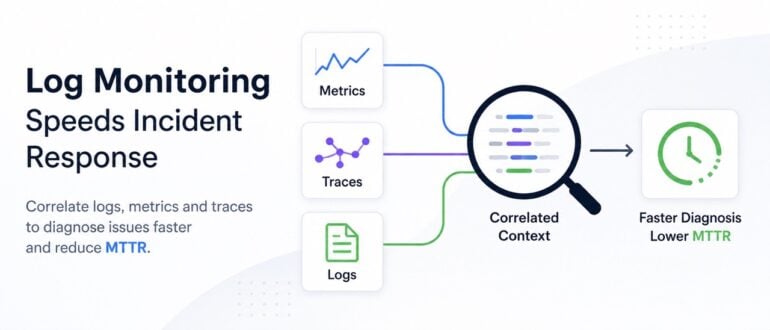
Why Log Monitoring Is the Missing Link in Most Incident Response Workflows
Modern engineering teams have invested heavily in observability. Dashboards are populated, alerts are configured, on-call rotations are set. Yet when production incidents occur, the average time to resolution hasn't dropped nearly as ...

From Reactive Monitoring to AI-Driven Operational Intelligence
Traditional monitoring often meant chasing alerts and toggling between dashboards after an issue had already impacted users. AWS CloudWatch — long the backbone of metrics, logs and traces on AWS — is ...

On-Call: The Silent Force Shaping Engineering Culture
There is a silent force shaping engineering culture inside every technology organization. It affects productivity, team morale, psychological safety, and long-term retention. And yet, it is rarely discussed in executive meetings or ...

The Five Biggest Mistakes Organizations Make When Implementing SRE
From cargo-culting Google's playbook to rushing AI-powered observability into production before the fundamentals are in place, here's where SRE transformations quietly go wrong, and how to course-correct. ...

AIOps Isn’t Optional Anymore: What Modern DevOps Teams Must Adapt To
AIOps is becoming essential for DevOps teams, enabling faster incident response, less alert noise and improved reliability at scale ...

AI Agents in DevOps: Hype vs. Reality in Production Pipelines
The demos look super cool! An AI agent detects a failing deployment, rolls it back, opens a GitHub issue, and notifies Slack — all before the on-call engineer has finished reading the ...

When Customer-Facing Systems Fail: How Incident Response and Observability Reduce MTTR
In a world of microservices and real-time interactions, MTTR is the ultimate metric for brand protection. Learn how observability and resilient architecture drive faster incident response ...

How We Got Here: Alert Fatigue to Decision Fatigue
AI and observability reduced alert fatigue, but decision fatigue remains. Decision architecture helps DevOps teams scale operational judgment ...
What to do About AI’s Forced Rethink of Reliability in Modern DevOps
As systems become more distributed and AI-driven, traditional uptime metrics are no longer enough. The 2026 SRE Report shows how reliability is shifting toward user experience, speed, and business impact, and how ...

Tool Fragmentation is Breaking Delivery Context — Here’s What Teams are Learning
Explore the emerging crisis in application delivery caused by tool fragmentation in modern software development. This article discusses the need for semantic interoperability, context preservation, and a shift from linear pipelines to ...

Secrets Management Failures in CI/CD Pipelines
Explore the critical role of secrets management in CI/CD pipelines and its impact on cybersecurity. This article highlights the risks of credential exposure, the importance of implementing strong security practices, and how ...
SRE vs. DevOps is a False Choice: Here’s the Unified Model That Works
DevOps and site reliability engineering (SRE) are complementary strategies that enhance both speed and reliability in software development. While DevOps focuses on collaboration and automation to break down silos between development and ...
